在广告点击率预估场景中,特征工程绝对是最重要的工作,没有之一。能否从海量的数据中找到最有效的特征,决定了一个算法工程师每周是否可以加上一个鸡腿。在实践中我们发现,广告的实时反馈 CTR 特征是一个可以让工程师加鸡腿的特征,这里就来聊聊它的正确使用方法。
1. 为什么有用
广告的实时反馈 CTR 特征的意思就是当前的广告正在投放,已经投放一部分了,这部分的点击率基本可以认为是这个广告的点击率了,也可以认为是这个广告质量的体现,把它作为点击率预估的特征之一相当于把目标 \(y\) 的信息带入了 \(\boldsymbol{x}\) 中,说白了就是合法的作弊了。
2. 特征分段
互联网广告的点击率符合一个长尾分布,叫做对数正态分布,其概率密度是下图(注意这个是假设,不代表真实的数据,从真实的数据观察是符合这么样的一个形状的,雅虎的研究论文 [3] 说它符合beta分布)。
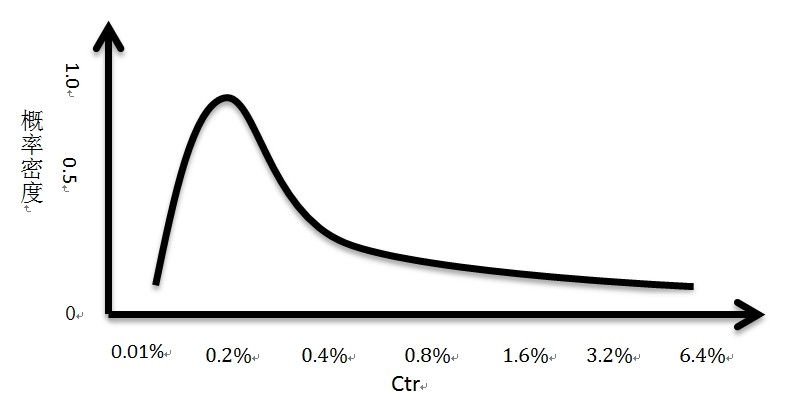
可以看到,大部分广告的点击率都是在某一个不大的区间内的,点击率越高的广告越少,同时这些广告覆盖的流量也少。换句话说,点击率在 0.2% 左右的时候,如果广告 a 的点击率是 0.2%,广告 b 的点击率是 0.25%,广告 b的点击率比广告 a 高 0.05%,其实足以表示广告 b 比广告 a 好不少;但是点击率在 1.0% 左右的的时候,广告 a 点击率是 1.0%,广告 b 的点击率是 1.05%,并不表示广告 b 比广告 a 好很多,因为在这 0.05% 的区间内的广告并不多,两个广告基本可以认为差不多的。
也就是说点击率在不同的区间,应该考虑不同的权重系数,因为广告实时反馈 CTR 特征与用户对广告的点击的概率不是完全的正相关性,有可能值越大特征越重要,也有可能值增长到了一定程度,重要性就下降了。对于这样的问题,有人提出了对连续特征进行离散化。他们认为,特征的连续值在不同的区间的重要性是不一样的,所以希望连续特征在不同的区间有不同的权重,实现的方法就是对特征进行划分区间,每个区间为一个新的特征。具体实现可以使用等频离散化方式或者是决策树的方式。实际的应用表明,离散化的特征能拟合数据中的非线性关系,取得比原有的连续特征更好的效果,而且在线上应用时,无需做乘法运算,也加快了计算 ctr 的速度。
3. 贝叶斯平滑
事实当然没有这么美好,在实际的应用中,如果某个 (或某类,下同) 广告的曝光比较小 (新广告或者小广告),那么它的实时反馈 CTR 特征是不置信的,而且短时间内会变化较大,比如一个广告曝光了 100 次,有 2 次点击,那么 ctr 就是 2%,但是当这个广告投曝光到了 1000 次的时候,点击只有 10 次,点击率是 1%,这里就相差了一倍了。
\[\mathrm{CTR}=\frac{\mathrm{\#click}}{\mathrm{\#impression}}\]对于这种广告,线上预估时的分段和后续特征关联时的分段很容易不一致,因此会导致训练和预测的紊乱,引起线上出现较大的 bias,而线下的离线 bias 又很正常的情况。尤其是当使用在线学习框架的时候,这种情况更为严重。所以我们需要对计算得到的 ctr 进行某种平滑后再使用,平滑方法有很多种,这里介绍下文章 [3] 里的贝叶斯平滑方法。
我们先做如下两点假设:
- 每个广告都有其自身的 CTR,这个值 \(r\) 服从参数为 \(\alpha\) 和 \(\beta\) 的 Beta 分布,\(r\sim\mathrm{Beta}(\alpha,\beta)\),即 \(p(r\vert\alpha,\beta)=\frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}r^{\alpha-1}(1-r)^{\beta-1}\)。
- 每个广告的点击数 \(C\) 服从 Binomial 分布,\(C\sim\mathrm{Binomial}(I,r)\),即 \(p(C\vert I,r)\propto r^{C}(1-r)^{I-C}\),其中 \(I\) 是曝光数。
假设一共有 \(N\) 个广告,广告的曝光次数为 (\(I_1,I_2,…,I_N\)),点击次数为 (\(C_1,C_2,…,C_N\)),则所有广告点击次数的似然函数为:
\[\begin{align*} P(C_1,...,C_N\vert I_1,...I_N,\alpha,\beta)&=\prod_{i=1}^{N}p(C_i\vert I_i,\alpha,\beta)=\prod_{i=1}^{N}\int_{r_i}p(C_i,r_i\vert I_i,\alpha,\beta)\mathrm{d}r_i \\ &=\prod_{i=1}^N\int_{r_i}p(C_i\vert I_i,r_i)p(r_i\vert\alpha,\beta)\mathrm{d}r_i \\ &=\prod_{i=1}^{N}\int_{r_i}r_i^{C_i}(1-r_i)^{I_i-C_i}\frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}r_i^{\alpha-1}(1-r_i)^{\beta-1}\mathrm{d}r_i \\ &=\prod_{i=1}^{N}\frac{\Gamma(\alpha+\beta)}{\Gamma(I_i+\alpha+\beta)}\frac{\Gamma(C_i+\alpha)}{\Gamma(\alpha)}\frac{\Gamma(I_i-C_i+\beta)}{\Gamma(\beta)} \end{align*}\]3.1 矩估计
为了求得 \(\alpha\) 和 \(\beta\),我们也可以用简单的矩估计来算。因为我们已经假定每个广告的 CTR 服从参数为 \(\alpha\) 和 \(\beta\) 的 Beta 分布,那么我们让总体的原点矩估等于样本的原点矩,即可解出参数。
\[mean=E(r)=\frac{\alpha}{\alpha+\beta}\] \[var=D(r)=\frac{\alpha\beta}{(\alpha+\beta)^2(\alpha+\beta+1)}\]所以
\[\alpha=[mean*(1-mean)/var-1]*mean\] \[\beta=[mean*[1-mean]/var-1]*(1-mean)\]3.2 Fixed-point ineration
为了求得似然函数的最大值,对上面的似然函数取对数得到对数似然函数后再分别对 \(\alpha\) 和 \(\beta\) 求导: \(\begin{align*} \frac{\mathrm{d}\mathrm{log}P(C_1,...,C_N\vert I_1,...I_N,\alpha,\beta)}{\mathrm{d}\alpha}&=\sum_{i=1}^N[\Psi(\alpha+\beta)-\Psi(I_i+\alpha+\beta)+\Psi(C_i+\alpha)-\Psi(\alpha)] \\ \frac{\mathrm{d}\mathrm{log}P(C_1,...,C_N\vert I_1,...I_N,\alpha,\beta)}{\mathrm{d}\beta}&=\sum_{i=1}^N[\Psi(\alpha+\beta)-\Psi(I_i+\alpha+\beta)+\Psi(I_i-C_i+\beta)-\Psi(\beta)] \end{align*}\)
其中的 \(\Psi(x)=\frac{\mathrm{d}}{\mathrm{d}x}\mathrm{ln}\Gamma(x)\) 是 digamma 函数,可以通过 Bernardo 算法进行计算,当然也可以参考另一篇文章 这里 进行快速的数值计算。最后通过 fixed-point interation (Minka, 2013) 方法可以得到如下的迭代公式:
\[\begin{align*} \alpha^{new}&=\alpha\frac{\sum_{i=1}^N[\Psi(C_i+\alpha)-\Psi(\alpha)]}{\sum_{i=1}^N[\Psi(I_i+\alpha+\beta)-\Psi(\alpha+\beta)]} \\ \beta^{new}&=\beta\frac{\sum_{i=1}^N[\Psi(I_i-C_i+\beta)-\Psi(\beta)]}{\sum_{i=1}^N[\Psi(I_i+\alpha+\beta)-\Psi(\alpha+\beta)]} \end{align*}\]初始值可以用矩估计的方式得到,然后通过上述迭代公式迭代计算得到 \(\alpha=\hat\alpha\) 和 \(\beta=\hat\beta\) 后,即可用于平滑广告的点击率了:
\[r_i=\frac{C_i+\hat\alpha}{I_i+\hat\alpha+\hat\beta}\]一些分析见参考文章[5]
3.3 EM 算法
见参考文章[5]